





The era of small language models has just begun. “LLM model size competition is intensifying… backwards!” quipped OpenAI cofounder Andrej Karpathy, reflecting on the recent announcements about GPT-4o mini and other small language models (SLMs).
This week was notable for the release of several SLMs. OpenAI released GPT-4o mini, a highly cost-efficient model designed to expand AI applications by making intelligence more affordable. Priced at $0.15 per million input tokens and $0.6 per million output tokens, GPT-4o mini is 30x cheaper than GPT-40 and 60% cheaper than GPT-3.5 Turbo.
On the other hand, Paris-based AI startup Mistral AI, in collaboration with NVIDIA, released Mistral NeMo, a 12 billion parameter model with a 128k token context length. Benchmarked against Gemma 2 9B and Llama 3 8B, it excels in reasoning, world knowledge, and coding accuracy. Mistral NeMo is particularly effective in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. Not only that, Mistral also launched MathΣtral, a specialised 7B model for advanced mathematical reasoning and scientific exploration,
A few days ago, Hugging Face also released a new series of compact language models called SmolLM, available in three sizes: 130M, 350M, and 1.7B parameters. These models are perfect for use on local devices such as laptops and phones, eliminating the need for cloud-based resources and significantly reducing energy consumption.
Similarly, H2O.ai introduced H2O-Danube3, a new series of SLMs to bring AI capabilities to mobile devices. The series includes two models: H2O-Danube3-4B, trained on 6 trillion tokens, and H2O-Danube3-500M, trained on 4 trillion tokens.
Apple too entered the game, releasing a 7B model called DCLM-BASELINE 7B, along with its weights, training code, and dataset. Trained on 2.5 trillion tokens from open datasets, the model primarily uses English data and features a 2048-token context window.
In China, Alibaba released Qwen’s Base and Instruct models in five sizes, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B, trained on data in 27 additional languages besides English and Chinese.
Small Is the New Big
SLMs or specialised models are going to be the future, alongside generalised models like GPT-4 or Claude 3.5 Sonnet. “For everyday use, an 8B or maybe 70B LLM will suffice. If you don’t want to test a model to the max, you don’t need a SOTA model. For everyday questions, which now appear in all training data, smaller models are sufficient,” posted a user on X.
“Both specialised and generic models will coexist, one is not a replacement for the other. It’s the wrong dream to believe we only need one API such as OpenAI. We will need both mega models aiming for AGI and specialised micro models that can integrate into today’s workflows,” said Pramod Varma, chief architect of Aadhaar, in a recent interaction with AIM.
In India, Gnani.ai recently launched a series of voice-first SLMs, which are trained on millions of audio hours of proprietary audio datasets and billions of Indic language conversations, capturing the rich diversity of dialects, accents, and linguistic nuances prevalent across the country.
Abacus.AI chief Bindu Reddy has predicted that in the next five years, smaller models will become more efficient, LLMs will continue to become cheaper to train, and LLM inference will become widespread. “We should expect to see several Sonnet 3.5 class models that are 100x smaller and cheaper in the next one to two years.”
Earlier this year, Microsoft unveiled Phi-3-Mini, a 3.8 billion parameter language model trained on an extensive dataset of 3.3 trillion tokens. Despite its compact size, the Phi-3-Mini boasts performance levels that rival larger models such as Mixtral 8x7B and GPT-3.5.
On similar lines, Karpathy explained that the reason current models are so large is that the training process is still quite wasteful: “We’re asking them to memorise the internet, and, remarkably, they do and can, e.g., recite SHA hashes of common numbers or recall really esoteric facts.”
“But imagine if you were going to be tested, closed book, on reciting arbitrary passages of the internet given the first few words. This is the standard (pre)training objective for models today,” he added. He noted that the ability to demonstrate thinking (e.g., reasoning) is closely tied to the amount of knowledge the model has learned from the training data.
He further explained that in the future, as larger models help refine and optimise the training process, smaller models will emerge. “The models have to first get larger before they can get smaller because we need their (automated) help to refactor and mould the training data into ideal, synthetic formats.”
Cost Effective
The constant use of LLMs also has its drawbacks, including high inference costs and energy consumption. SLMs, such as Gemma or LLaMA 8B, are very cost-effective as they require less compute and their inferences consume less energy.
OpenAI used to spend around $700,000 daily to run ChatGPT. With GPT-4o mini, that cost may decrease to some extent. Moreover, since SLMs can run locally on devices without requiring the cloud, they don’t need extensive AI infrastructure and GPUs.
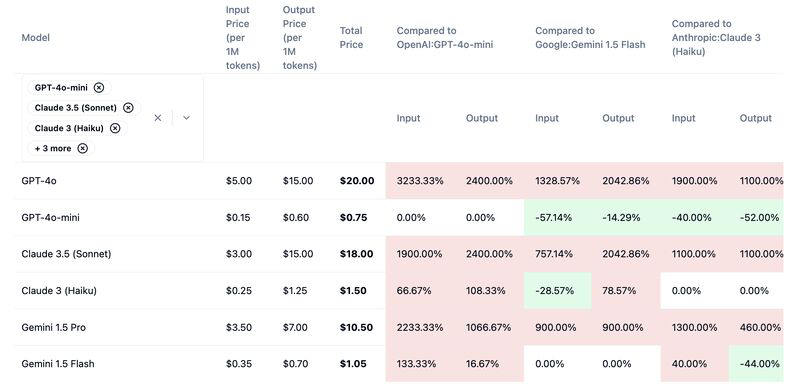
Compared to Claude 3.5 Sonnet and Google’s Gemini 1.5 Pro, OpenAI’s GPT-4o mini is significantly cheaper. According to Hugging Face, GPT-4o mini is the least expensive, with a combined input and output cost of just $0.75 per million tokens.
Ola Krutrim chief Bhavish Aggarwal recently pointed out that a single H100 NVIDIA GPU consumes 30 times more electricity in a year than an Ola S1 scooter. “An H100 GPU requires around 8.7 MWh of energy per year, whereas an S1 requires 0.25 MWh/year. Need a lot of electricity in the future!” he said.
However that is now changing as Karpathy recently demonstrated that today one can train GPT-2 on their own for ~$672, running on one 8XH100 GPU node for 24 hours. “Incredibly, the costs have come down dramatically over the last five years due to improvements in compute hardware (H100 GPUs), software (CUDA, cuBLAS, cuDNN, FlashAttention) and data quality (e.g. the FineWeb-Edu dataset),” he said.
On the other hand, TWO AI chief Pranav Mistry claimed that the future is in 1-bit LLMs as they have multiple advantages, meaning that they can fit on smaller chips, require less memory, and have faster processing.
SLMs, the future of generative AI?
One question haunts enterprises: the balance between the impressive capabilities of SLMs and their potential drawbacks compared to private instances of large models, and whether small models represent the future of generative AI.
“Technology is rapidly evolving how we operate and train. Three months ago, using an SLM isolated in a customer’s private database might have seemed like a drawback compared to a private instance of a large public model,” said Upstage’s Kasey Roh, on the sidelines of the recent AWS Summit in Washington DC.
The South Korean company has built an SLM called Solar, one of the top-ranked models on the HuggingFace Open LLM leaderboard, and a finetune of Llama 2.
Further, Roh said that to address the challenges of SLMs, the company has now entered into a subscription model with its customers, allowing them to continuously train and fine-tune models with the latest data points.
She believes that this modular and standardised approach significantly mitigates the drawbacks of using small private models. “Once we have a more complete set of the tools and programmes available, I think that the drawback of having a small model that’s private can be largely addressable,” concluded Roh.























