





A recurrent neural network is a type of ANN that is used when users want to perform predictive operations on sequential or time-series based data. These Deep learning layers are commonly used for ordinal or temporal problems such as Natural Language Processing, Neural Machine Translation, automated image captioning tasks and likewise. Today’s modern voice assistance devices such as Google Assistance, Alexa, Siri are incorporated with these layers to fulfil hassle-free experiences for users.
What is the difference between RNN and CNN?
The main difference between the RNN and CNN is that RNN is incorporated with memory to take any information from prior inputs to influence the Current input and output. Training methods for this network are the same. While traditional neural networks assume that both input and output are independent of each other, RNN gives the output based on previous input and its context.
Another distinguishing parameter is that RNN shares parameters across each layer of the network. While feedforward networks have different weights across each node, recurrent neural networks share the same weight parameter within each layer of the network.
Below at left one is a representation of standard RNN and the right one is a representation of Feed-Forward Network.

In the last few years for RNN’s, there has been an incredible success in a variety of problems such as speech recognition, language modelling, translation, image captioning and list goes on.
Let’s take a look at a single unit of RNN architecture. Where it takes input from the previous step and current state Xt and incorporated with Tanh as an activation function, here we can explicitly change the activation function.

Sometimes we only need to look at recent information to perform a present task. But this is not the case we face all the time. When a standard RNN network is exposed to long sequences or phrases it tends to lose the information because it can not store the long sequences and as the methodology is concerned it focuses only on the latest information available at the node. This problem is commonly referred to as Vanishing gradients.
In RNN to train networks, we backpropagate through time and at each time step or loop operation gradient is being calculated and the gradient is used to update the weights in the networks. Now if the effect of the previous sequence on the layer is small then the relative gradient is calculated small. Then if the gradient of the previous layer is smaller then this makes weights to be assigned to the context smaller and this effect is observed when we deal with longer sequences. Due to this network does not learn the effect of earlier inputs and thus causing the short term memory problem.
To overcome this problem specialized versions of RNN are created like LSTM, GRU, Time Distributed layer, ConvLSTM2D layer.
Working of LSTM
Long Short Term Memory in short LSTM is a special kind of RNN capable of learning long term sequences. They were introduced by Schmidhuber and Hochreiter in 1997. It is explicitly designed to avoid long term dependency problems. Remembering the long sequences for a long period of time is its way of working.

The popularity of LSTM is due to the Getting mechanism involved with each LSTM cell. In a normal RNN cell, the input at the time stamp and hidden state from the previous time step is passed through the activation layer to obtain a new state. Whereas in LSTM the process is slightly complex, as you can see in the above architecture at each time it takes input from three different states like the current input state, the short term memory from the previous cell and lastly the long term memory.
These cells use the gates to regulate the information to be kept or discarded at loop operation before passing on the long term and short term information to the next cell. We can imagine these gates as Filters that remove unwanted selected and irrelevant information. There are a total of three gates that LSTM uses as Input Gate, Forget Gate, and Output Gate.
Input Gate
The input gate decides what information will be stored in long term memory. It only works with the information from the current input and short term memory from the previous step. At this gate, it filters out the information from variables that are not useful.
Forget Gate
The forget decides which information from long term memory be kept or discarded and this is done by multiplying the incoming long term memory by a forget vector generated by the current input and incoming short memory.
Output Gate
The output gate will take the current input, the previous short term memory and newly computed long term memory to produce new short term memory which will be passed on to the cell in the next time step. The output of the current time step can also be drawn from this hidden state.
So this is all about the mechanism of LSTM to realise this with practical implementation. Here I have demonstrated the LSTM use case in which you can check input and output sequences with their shape.
Working of GRU
The workflow of the Gated Recurrent Unit, in short GRU, is the same as the RNN but the difference is in the operation and gates associated with each GRU unit. To solve the problem faced by standard RNN, GRU incorporates the two gate operating mechanisms called Update gate and Reset gate.
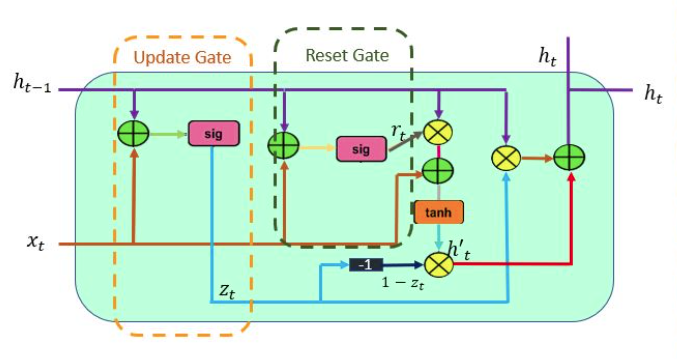
Update gate
The update gate is responsible for determining the amount of previous information that needs to pass along the next state. This is really powerful because the model can decide to copy all the information from the past and eliminate the risk of vanishing gradient.
Reset gate
The reset gate is used from the model to decide how much of the past information is needed to neglect; in short, it decides whether the previous cell state is important or not.
First, the reset gate comes into action it stores relevant information from the past time step into new memory content. Then it multiplies the input vector and hidden state with their weights. Next, it calculates element-wise multiplication between the reset gate and previously hidden state multiple. After summing up the above steps the non-linear activation function is applied and the next sequence is generated.
This is all about the operation of GRU, the practical examples are included in the notebooks.
LSTM Vs GRU
Now we have seen the operation of both the layers to combat the problem of vanishing gradient. So you might wonder which one is to use? As GRU is relatively approaching its tradeoffs haven’t been discussed yet.
According to empirical evaluation, there is not a clear winner. The basic idea of using a getting mechanism to learn long term dependencies is the same as in LSTM.
The few differencing points are as follows:
The GRU has two gates, LSTM has three gates
GRU does not possess any internal memory, they don’t have an output gate that is present in LSTM
In LSTM the input gate and target gate are coupled by an update gate and in GRU reset gate is applied directly to the previous hidden state. In LSTM the responsibility of reset gate is taken by the two gates i.e., input and target.
Conclusion
Through this article, we have understood the basic difference between the RNN, LSTM and GRU units. From working of both layers i.e., LSTM and GRU, GRU uses less training parameter and therefore uses less memory and executes faster than LSTM whereas LSTM is more accurate on a larger dataset. One can choose LSTM if you are dealing with large sequences and accuracy is concerned, GRU is used when you have less memory consumption and want faster results.

























