





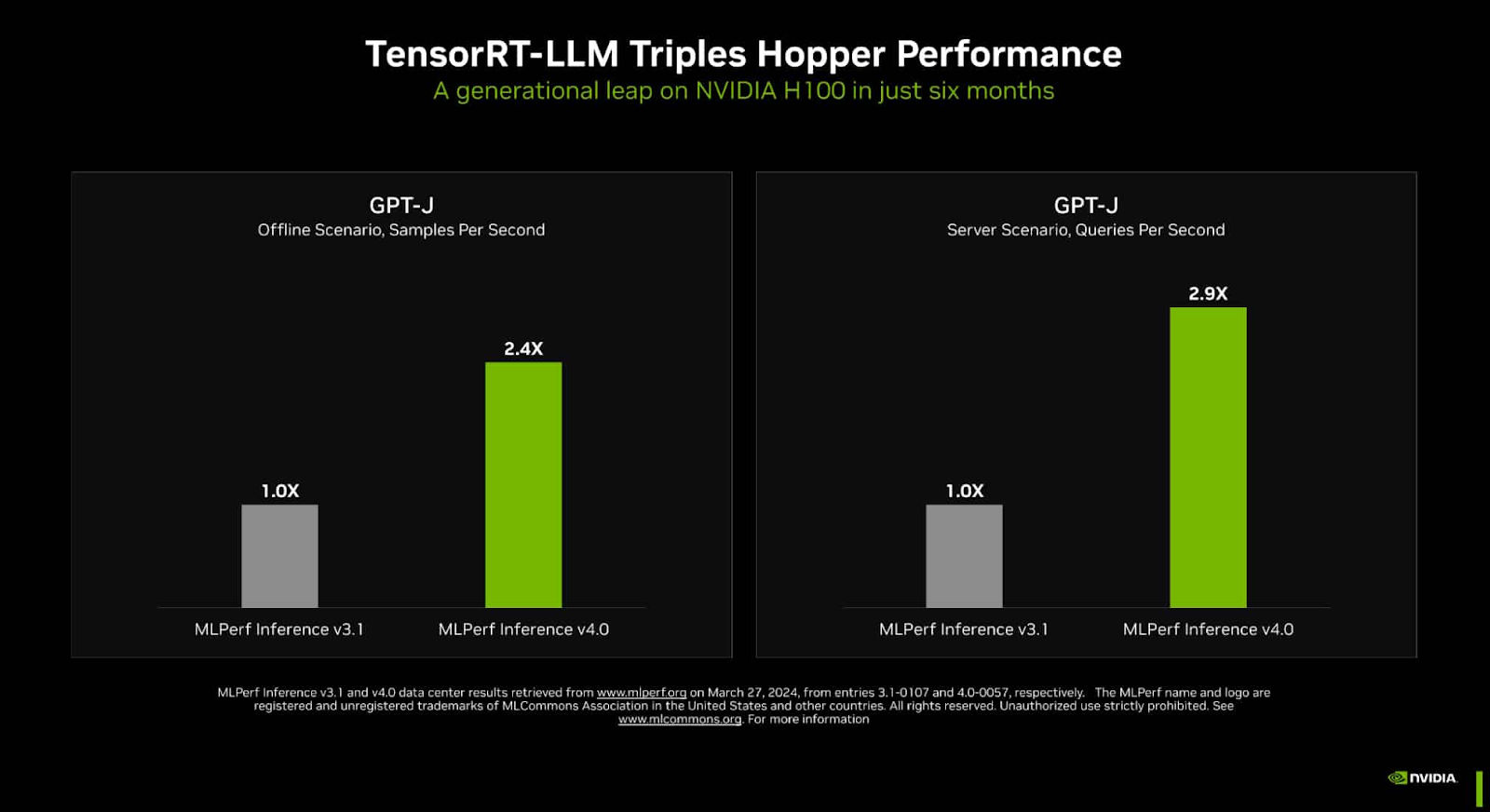
NVIDIA has solidified its dominance in generative AI with the unveiling of performance metrics in the latest MLPerf benchmarks. Leveraging TensorRT-LLM, specifically designed to streamline inference tasks for LLMs, NVIDIA’s Hopper architecture GPUs demonstrated a 3x increase in performance on the GPT-J LLM over results recorded merely six months prior.
Companies at the forefront of innovation are harnessing TensorRT-LLM to optimise their models, facilitated further by NVIDIA NIM – a suite of inference microservices encompassing powerful engines such as TensorRT-LLM. This integrated approach simplifies the deployment of NVIDIA’s inference platform, offering businesses unparalleled efficiency and flexibility.
The recent MLPerf benchmarks unveiled a significant leap in generative AI capabilities, with TensorRT-LLM running on NVIDIA’s latest H200 Tensor Core GPUs. These memory-enhanced GPUs, making their debut in the MLPerf arena, achieved remarkable throughput, generating up to 31,000 tokens per second on the Llama 2 70B benchmark.
The success of the H200 GPUs also underscores the innovative strides made in thermal management, with custom solutions contributing to performance gains of up to 14%. These advancements, exemplified by systems builders’ creative implementations in NVIDIA MGX designs, further elevate the performance capabilities of Hopper GPUs.
NVIDIA has commenced the shipment of H200 GPUs today, which will soon be accessible through nearly 20 prominent system builders and cloud service providers.
With an impressive memory bandwidth of almost 5 TB/second, the GH200 Superchips have demonstrated exceptional performance, particularly in memory-intensive MLPerf assessments such as recommender systems.
Employing a technique known as structured sparsity—a method aimed at reducing computations, initially introduced with NVIDIA A100 Tensor Core GPUs—NVIDIA engineers achieved speed enhancements of up to 33% on inference with Llama 2.
In response to the escalating sizes of LLM models, NVIDIA’s founder and CEO Jensen Huang revealed during last week’s GTC that the upcoming NVIDIA Blackwell architecture GPUs will deliver heightened performance levels necessary for multi trillion-parameter AI models.


























