DeepSeek, a company based in China which aims to “unravel the mystery of AGI with curiosity,” has released DeepSeek LLM, a 67 billion parameter model trained meticulously from scratch on a dataset consisting of 2 trillion tokens.
Available in both English and Chinese languages, the LLM aims to foster research and innovation. The research community is granted access to the open-source versions, DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat.
Check out the GitHub repository here.
The model is available under the MIT licence.
DeepSeek LLM 67B Base has showcased unparalleled capabilities, outperforming the Llama 2 70B Base in key areas such as reasoning, coding, mathematics, and Chinese comprehension. Particularly, its proficiency in coding is highlighted by an outstanding HumanEval Pass@1 score of 73.78, and in mathematics, it achieves remarkable scores, including GSM8K 0-shot: 84.1 and Math 0-shot: 32.6.

The model’s generalisation abilities are underscored by an exceptional score of 65 on the challenging Hungarian National High School Exam.
DeepSeek LLM 7B/67B models, including base and chat versions, are released to the public on GitHub, Hugging Face and also AWS S3. Access to intermediate checkpoints during the base model’s training process is provided, with usage subject to the outlined licence terms.
In-depth evaluations have been conducted on the base and chat models, comparing them to existing benchmarks. Results reveal DeepSeek LLM’s supremacy over LLaMA-2, GPT-3.5, and Claude-2 in various metrics, showcasing its prowess in English and Chinese languages.
The evaluation extends to never-before-seen exams, including the Hungarian National High School Exam, where DeepSeek LLM 67B Chat exhibits outstanding performance.
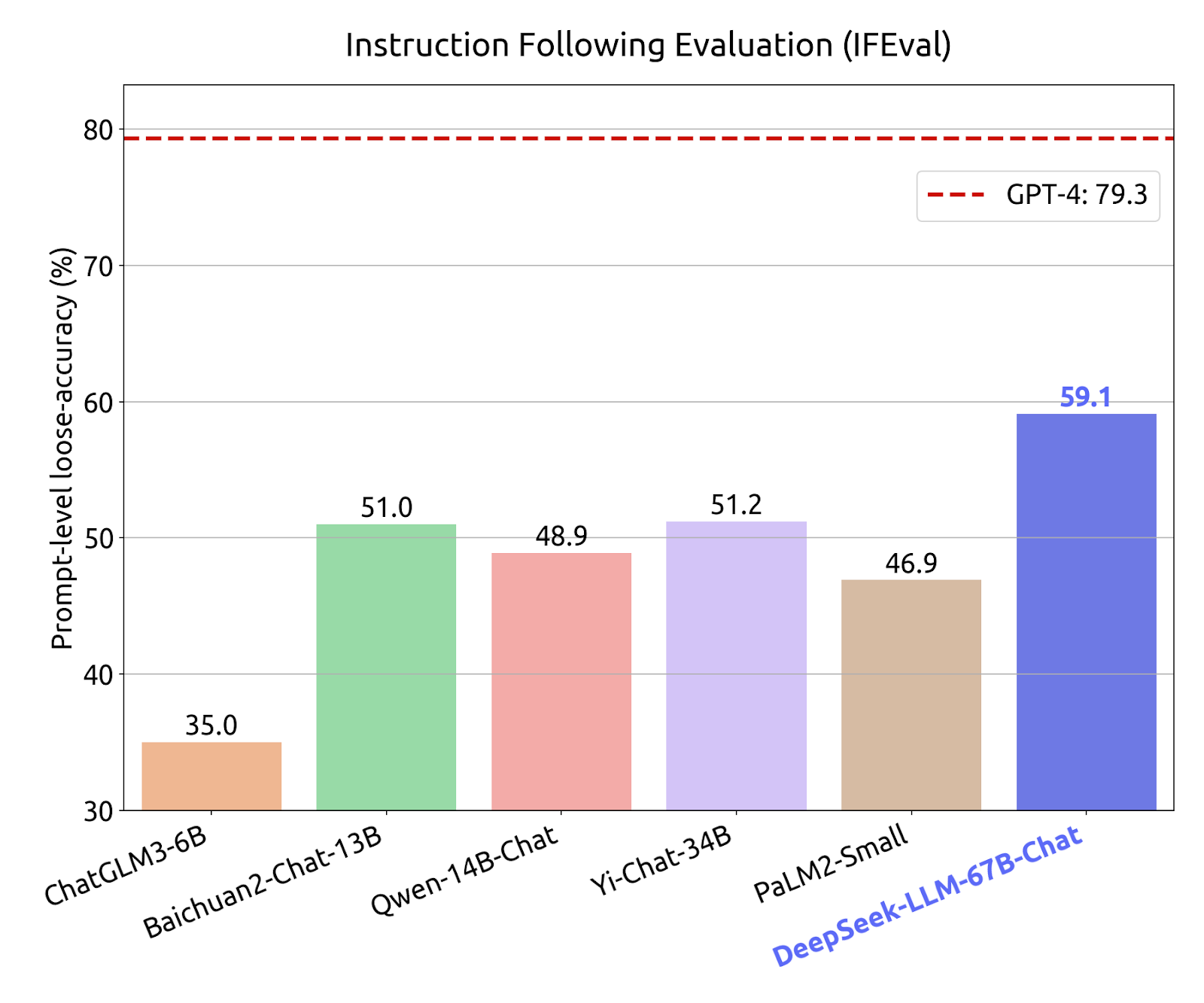
Experimentation with multi-choice questions has proven to enhance benchmark performance, particularly in Chinese multiple-choice benchmarks. By incorporating 20 million Chinese multiple-choice questions, DeepSeek LLM 7B Chat demonstrates improved scores in MMLU, C-Eval, and CMMLU.
DeepSeek LLM’s pre-training involved a vast dataset, meticulously curated to ensure richness and variety. The architecture, akin to LLaMA, employs auto-regressive transformer decoder models with unique attention mechanisms. The pre-training process, with specific details on training loss curves and benchmark metrics, is released to the public, emphasising transparency and accessibility.
Recently, Alibaba, the chinese tech giant also unveiled its own LLM called Qwen-72B, which has been trained on high-quality data consisting of 3T tokens and also an expanded context window length of 32K. Not just that, the company also added a smaller language model, Qwen-1.8B, touting it as a gift to the research community.