





The purpose of this research is to put together the 7 most common types of classification algorithms along with the python code: Logistic Regression, Naïve Bayes, Stochastic Gradient Descent, K-Nearest Neighbours, Decision Tree, Random Forest, and Support Vector Machine
Structured Data Classification
Classification can be performed on structured or unstructured data. Classification is a technique where we categorize data into a given number of classes. The main goal of a classification problem is to identify the category/class to which a new data will fall under.
Few of the terminologies encountered in machine learning – classification:
- Classifier: An algorithm that maps the input data to a specific category.
- Classification model: A classification model tries to draw some conclusion from the input values given for training. It will predict the class labels/categories for the new data.
- Feature: A feature is an individual measurable property of a phenomenon being observed.
- Binary Classification: Classification task with two possible outcomes. Eg: Gender classification (Male / Female)
- Multi-class classification: Classification with more than two classes. In multi class classification each sample is assigned to one and only one target label. Eg: An animal can be cat or dog but not both at the same time
- Multi-label classification: Classification task where each sample is mapped to a set of target labels (more than one class). Eg: A news article can be about sports, a person, and location at the same time.
The following are the steps involved in building a classification model:
- Initialize the classifier to be used.
- Train the classifier: All classifiers in scikit-learn uses a fit(X, y) method to fit the model(training) for the given train data X and train label y.
- Predict the target: Given an unlabeled observation X, the predict(X) returns the predicted label y.
- Evaluate the classifier model
Dataset Source and Contents
The dataset contains salaries. The following is a description of our dataset:
- of Classes: 2 (‘>50K’ and ‘<=50K’)
- of attributes (Columns): 7
- of instances (Rows): 48,842
This data was extracted from the census bureau database found at:
http://www.census.gov/ftp/pub/DES/www/welcome.html
Exploratory Data Analysis
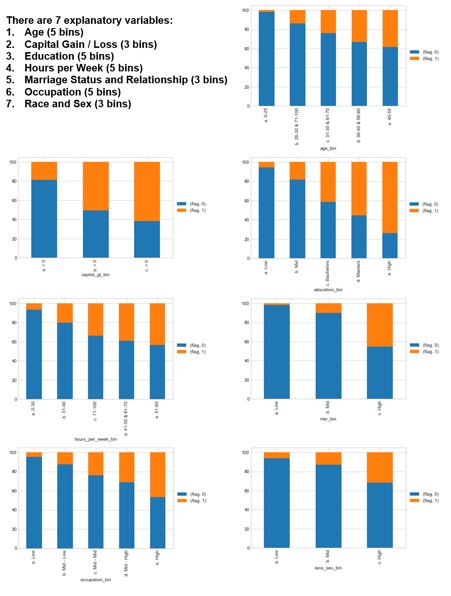
Types of Classification Algorithms with Python
1. Logistic Regression
Definition: Logistic regression is a machine learning algorithm for classification. In this algorithm, the probabilities describing the possible outcomes of a single trial are modelled using a logistic function.
Advantages: Logistic regression is designed for this purpose (classification), and is most useful for understanding the influence of several independent variables on a single outcome variable.
Disadvantages: Works only when the predicted variable is binary, assumes all predictors are independent of each other and assumes data is free of missing values.

2. Naïve Bayes
Definition: Naive Bayes algorithm based on Bayes’ theorem with the assumption of independence between every pair of features. Naive Bayes classifiers work well in many real-world situations such as document classification and spam filtering.
Advantages: This algorithm requires a small amount of training data to estimate the necessary parameters. Naive Bayes classifiers are extremely fast compared to more sophisticated methods.
Disadvantages: Naive Bayes is is known to be a bad estimator.

3. Stochastic Gradient Descent
Definition: Stochastic gradient descent is a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification.
Advantages: Efficiency and ease of implementation.
Disadvantages: Requires a number of hyper-parameters and it is sensitive to feature scaling.

4. K-Nearest Neighbours
Definition: Neighbours based classification is a type of lazy learning as it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the k nearest neighbours of each point.
Advantages: This algorithm is simple to implement, robust to noisy training data, and effective if training data is large.
Disadvantages: Need to determine the value of K and the computation cost is high as it needs to compute the distance of each instance to all the training samples.

5. Decision Tree
Definition: Given a data of attributes together with its classes, a decision tree produces a sequence of rules that can be used to classify the data.
Advantages: Decision Tree is simple to understand and visualise, requires little data preparation, and can handle both numerical and categorical data.
Disadvantages: Decision tree can create complex trees that do not generalise well, and decision trees can be unstable because small variations in the data might result in a completely different tree being generated.

6. Random Forest
Definition: Random forest classifier is a meta-estimator that fits a number of decision trees on various sub-samples of datasets and uses average to improve the predictive accuracy of the model and controls over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement.
Advantages: Reduction in over-fitting and random forest classifier is more accurate than decision trees in most cases.
Disadvantages: Slow real time prediction, difficult to implement, and complex algorithm.

7. Support Vector Machine
Definition: Support vector machine is a representation of the training data as points in space separated into categories by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
Advantages: Effective in high dimensional spaces and uses a subset of training points in the decision function so it is also memory efficient.
Disadvantages: The algorithm does not directly provide probability estimates, these are calculated using an expensive five-fold cross-validation.

Comparison Matrix
- Accuracy: (True Positive + True Negative) / Total Population
- Accuracy is a ratio of correctly predicted observation to the total observations. Accuracy is the most intuitive performance measure.
- True Positive: The number of correct predictions that the occurrence is positive
- True Negative: The number of correct predictions that the occurrence is negative
- F1-Score: (2 x Precision x Recall) / (Precision + Recall)
- F1-Score is the weighted average of Precision and Recall used in all types of classification algorithms. Therefore, this score takes both false positives and false negatives into account. F1-Score is usually more useful than accuracy, especially if you have an uneven class distribution.
- Precision: When a positive value is predicted, how often is the prediction correct?
- Recall: When the actual value is positive, how often is the prediction correct?
| Classification Algorithms | Accuracy | F1-Score |
| Logistic Regression | 84.60% | 0.6337 |
| Naïve Bayes | 80.11% | 0.6005 |
| Stochastic Gradient Descent | 82.20% | 0.5780 |
| K-Nearest Neighbours | 83.56% | 0.5924 |
| Decision Tree | 84.23% | 0.6308 |
| Random Forest | 84.33% | 0.6275 |
| Support Vector Machine | 84.09% | 0.6145 |
Code location: https://github.com/f2005636/Classification
Algorithm Selection
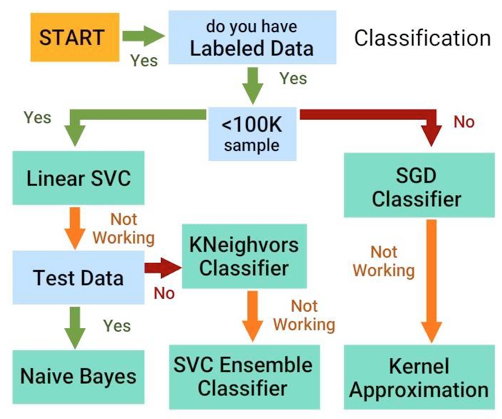
(Types of Classification Algorithms)

























