





Meta has finally dropped Llama 3, with a twist!
In its Community License Agreement conditions, the company has mentioned, “If you use the Llama Materials to create, train, fine-tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model name”, under the redistribution and use section.
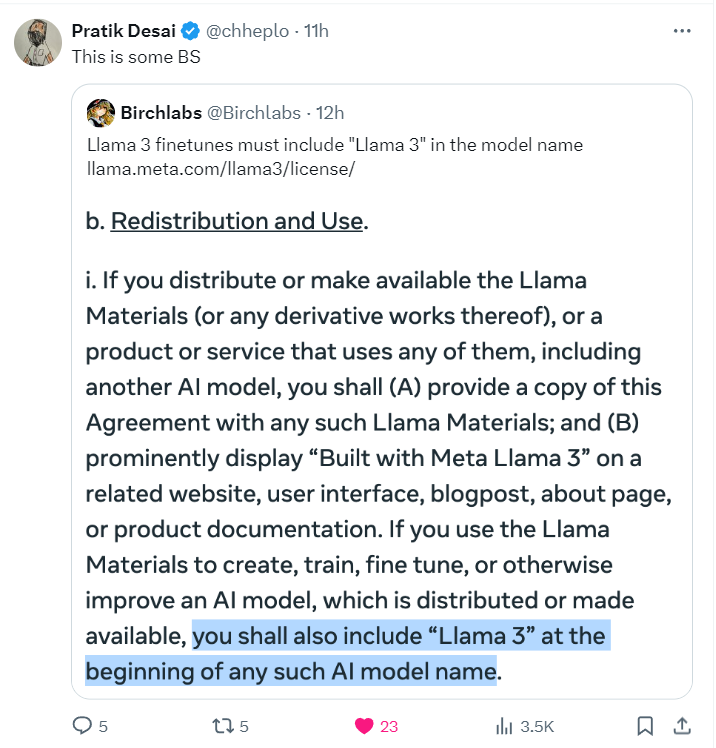
Source: X
As expected, this strange clause has sparked conversations among the AI community, with many debating its need, justification, and impact.
With many startups riding on the open-source AI wave, especially in India, making it an Open-Source AI champion, it would be interesting to note how this development gets implemented.
Would we see a name change for Kissan AI’s agri LLM Dhenu, Sarvam AI’s OpenHathi, PAiGPT, and other AI models in Indic languages like Ambari, Odia Llama, Tamil Llama, all based on the Llama 2 model?
Some are just having fun online over this latest development.

Introducing Llama 3
Meta has released Llama 3, the latest generation of its LLM. The model, available in 8B and 70B parameter versions, has been trained on over 15 trillion tokens, making it seven times larger than Llama 2’s dataset.
Llama 3 offers SOTA performance and enhanced reasoning and coding capabilities. Its training process is three times more efficient than its predecessor.
The 7B models outperforms Gemma and Mistral on all benchmarks and the 70B model outperforms Gemini Pro 1.5 and Claude 3 Sonnet. Meta is also training a model with more than 400 billion parameters.
Given its advancements, Meta’s push to include ‘Llama 3’ in the beginning of AI models that use it in their development, is a boost towards security and responsible use cases.


























