





After teasing the world with a glimpse on Microsoft Azure, Meta has finally dropped Llama 3, the latest generation of its LLM that offers SOTA performance and efficiency.
Click here to check out the model on GitHub.
The model is available in 8B and 70B parameter versions and has been trained on over 15 trillion tokens, making it seven times larger than Llama 2’s dataset. Llama 3 provides enhanced reasoning and coding capabilities, and its training process is three times more efficient than its predecessor.
The models are now also available on Hugging Face.
Meta is also training a model with more than 400 billion parameters which Mark Zuckerberg said in a Reel on Instagram is going to be the top performing model out there.
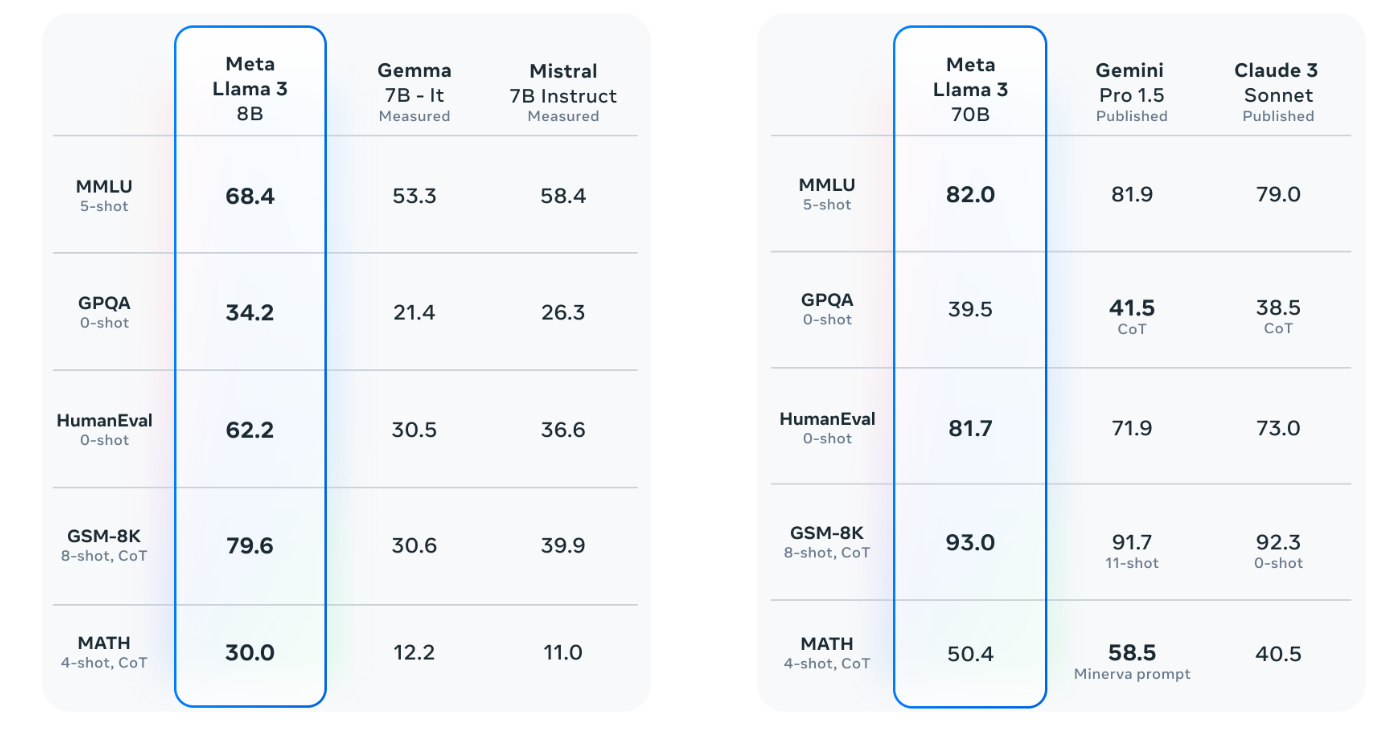
The 7B models outperforms Gemma and Mistral on all benchmarks and the 70B model outperforms Gemini Pro 1.5 and Claude 3 Sonnet.
Llama 3 models is now rolling out on Amazon SageMaker, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake. Additionally, the models will be compatible with hardware platforms provided by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
In addition to the model, Meta has incorporated its latest models into Meta AI, now powered by Llama 3, and expanded its availability across more countries. Meta AI is accessible through Facebook, Instagram, WhatsApp, Messenger, and the web, enabling users to accomplish tasks, learn, create, and engage with their interests.
Additionally, users will soon have the opportunity to experience multimodal Meta AI on Ray-Ban Meta smart glasses.
Meta AI is powered by Llama 3 and is now available in 13 new countries. It includes improved search capabilities and innovative web experiences. The latest updates in image generation on Meta AI allow users to create, animate, and share images with a simple text prompt.
The model uses a 128K-token vocabulary for more efficient language encoding, leading to significantly improved performance. To boost inference efficiency, grouped query attention (GQA) is implemented in both the 8B and 70B parameter models. The models were trained on sequences of 8,192 tokens, with masking to maintain document boundaries.
Llama 3’s training data consists of over 15 trillion tokens sourced from publicly available data, seven times larger than Llama 2’s dataset. The model was trained on two custom built 24k GPU clusters.
It includes four times more code and over 5% high-quality non-English data spanning 30+ languages, though English remains the most proficient. Advanced data-filtering methods, including heuristic filters and semantic deduplication, ensure top-quality training data.
Here is the sneak preview of the upcoming 400 billion parameter Llama 3 model.



























