





Researchers Albert Gu and Tri Dao from Carnegie Mellon and Together AI have introduced a groundbreaking model named Mamba, challenging the prevailing dominance of Transformer-based architectures in deep learning.
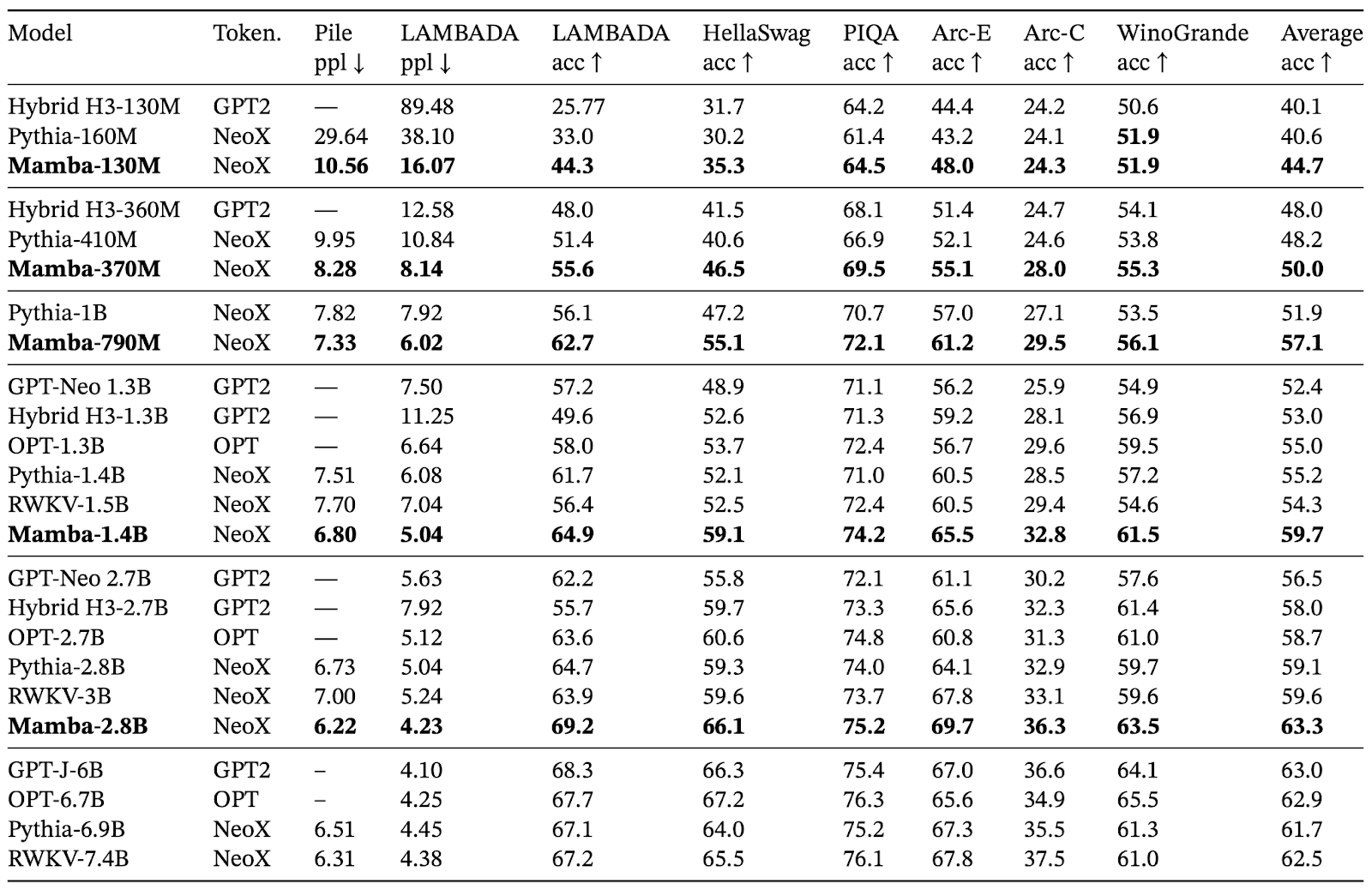
Their research unveils Mamba as a state-space model (SSM) that demonstrates superior performance across various modalities, including language, audio, and genomics. For example, the researchers tried their language modelling with the Mamba-3B model that outperformed Transformers based models of the same size and matched Transformers twice its size, both in pretraining and downstream evaluation.
Click here to check out the GitHub repository.
Mamba is presented as a state-of-the-art model with linear-time scaling, ultra-long context, and remarkable efficiency, outperforming Transformers in tasks it has been tested on.
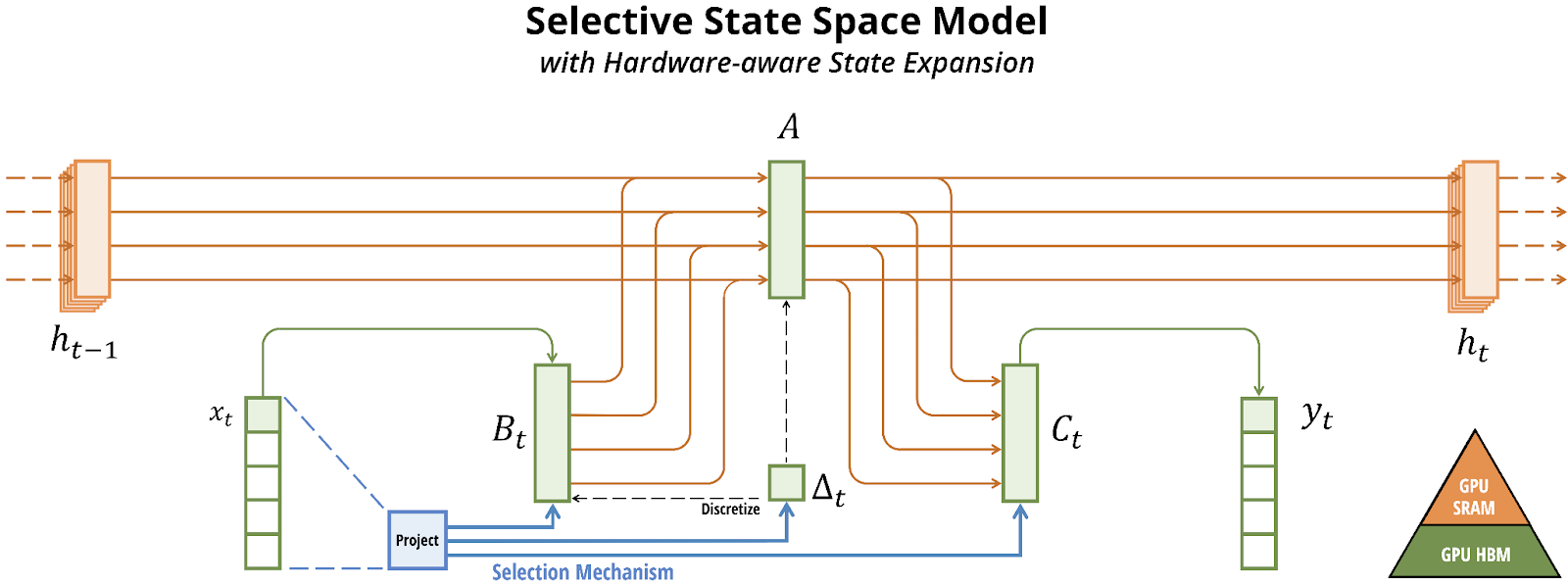
The model is built on the foundation of structured state space models (SSMs), showcasing promising results in information-dense data scenarios, particularly excelling in language modelling where previous subquadratic models have fallen short compared to Transformers.
The researchers emphasise Mamba’s efficiency through its selective SSM layer, designed to address the computational inefficiency of Transformers on long sequences up to a massive million sequence length, which is a major limitation in Transformers.
Installation details for Mamba include the use of causal Conv1d layers and the core Mamba package, with additional requirements such as Linux, NVIDIA GPU, PyTorch 1.12+, and CUDA 11.6+.
Mamba’s versatility is demonstrated through its integration into an end-to-end neural network, offering a comprehensive language model with varying model dimensions and layers.
Mamba provides pretrained models with different parameters and layers, showcasing its adaptability to various tasks and data sizes. Evaluations of Mamba’s performance involve running zero-shot evaluations using the lm-evaluation-harness library, with comparisons against other models such as EleutherAI’s pythia-160m.
The research identifies a key weakness in existing subquadratic-time architectures, attributing it to their inability to perform content-based reasoning. Mamba addresses this weakness by allowing selective propagation or forgetting of information along the sequence length dimension, demonstrating significant improvements over traditional models.
Despite the shift away from efficient convolutions, Mamba employs a hardware-aware parallel algorithm in recurrent mode, resulting in fast inference and linear scaling in sequence length.
Mamba emerges as a compelling contender challenging the Transformer paradigm, demonstrating superior performance in diverse modalities and promising advancements in the field of deep learning.



















