The various transformer designs have become the x-factor for a variety of complicated natural language processing and computer vision applications. In contrast to vision or visuals, you may have come upon a hazy image that signifies a lot to you. Various transformer-based techniques are available to restore such images, however, nearly all do not produce the desired results. So, in this post, we’ll talk about how to restore or reconstruct an image using the SwinIR transformer. The following are the main points to be discussed in this article.
Table Of Contents
- What is Image Restoration?
- Methods for Image Restoration
- How does SwinIR Restore the Images?
- Quick Start with SwinIR
Let’s start the discussion by understanding what is Image restoration.
What is Image Restoration?
Image restoration techniques such as image super-resolution (SR), image denoising, and JPEG compression artefact reduction strive to recreate a high-quality clean image from a low-quality degraded image. Image restoration is the process of estimating the clean, original image from a corrupted/noisy image.
Motion blur, noise, and camera misfocus are all examples of corruption. Image restoration is accomplished by reversing the blurring process, which is accomplished by imaging a point source and using the point source picture, also known as the Point Spread Function (PSF), to recover the image information lost during the blurring process.
Methods for Image Restoration
Convolutional neural networks (CNN) have become the major workhorse for picture restoration since numerous groundbreaking studies. The majority of CNN-based approaches place a premium on complex architecture designs like residual learning and dense connections. Although the performance is substantially better than traditional model-based techniques, they are nevertheless plagued by two major flaws in the fundamental convolution layer.
First, the substance of the interactions between pictures and convolution kernels is irrelevant. It’s possible that using the same convolution kernel to restore different image sections isn’t the ideal solution. Second, convolution is ineffective for long-range dependency modelling due to the notion of local processing.
Transformer, in contrast to CNN, uses a self-attention mechanism to capture global interactions across contexts and has demonstrated promising results in a variety of visual difficulties. However, image restoration vision Transformers divide the input image into patches of a predefined size (e.g., 48×48) and analyze each patch separately.
Two disadvantages necessarily arise as a result of such a technique. For starters, border pixels can’t use neighbouring pixels that aren’t in the patch to restore the image. Second, border artefacts around each patch may be introduced by the restored image. While patch overlapping can help solve this problem, it also adds to the computational load.
How does SwinIR Restore the Images?
SwinIR Transformer has shown a lot of promise because it combines the benefits of CNN and Transformer. On the one hand, because of the local attention mechanism, it has the benefit of CNN in processing images of huge size and leveraging the shifted window design, it has the advantage of Transformer in modeling long-range dependency. SwinIR is a Swin Transformer-based product.
SwinIR is made up of three different modules: shallow feature extraction, deep feature extraction, and high-quality image reconstruction. To preserve low-frequency information, the shallow feature extraction module employs a convolution layer to extract shallow features, which are then immediately transferred to the reconstruction module.
The residual Swin Transformer blocks (RSTB) that make up the deep feature extraction module use many Swin Transformer layers for local attention and cross-window interaction. In addition, we use a residual connection to give a shortcut for feature aggregation and add a convolution layer at the conclusion of the block for feature augmentation. Finally, the reconstruction module fuses shallow and deep features for high-quality image reconstruction.
SwinIR has various advantages over common CNN-based image restoration models: Interactions between visual content and attention weights that are content-based and can be viewed as spatially varying convolution. The shifted window approach allows for long-range dependence modelling. Better results with fewer parameters
SwinIR is made up of three modules: shallow feature extraction, deep feature extraction, and high-quality (HQ) image reconstruction (shown in the diagram below). For all restoration jobs, it uses the same feature extraction modules, but distinct reconstruction modules for various tasks.
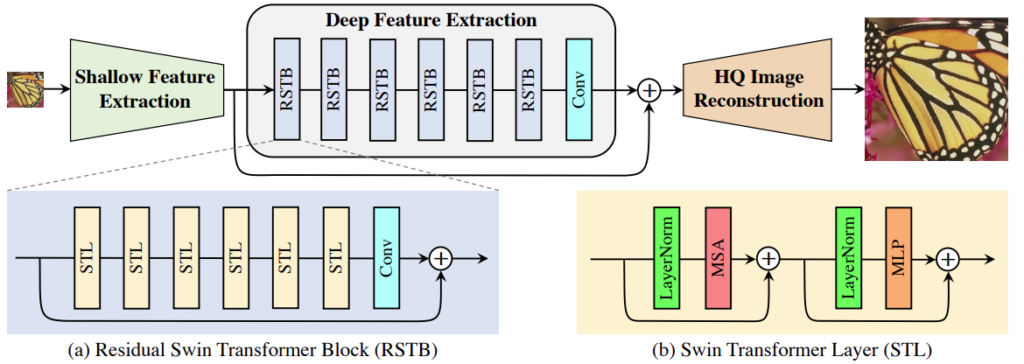
The architecture of SwinIR (Source)
When we provide a low-quality input image, it employs a three-layer convolutional layer to extract shallow features. The convolution layer excels in early visual processing, resulting in more stable optimization and improved results. It also gives a straightforward method for mapping the input picture space to a higher dimensional feature space. Shallow features mostly contain low-frequency content, whereas deep features concentrate on restoring lost high-frequency content.
Quick Start With SwinIR
As per the research paper, SwinIR achieves best-in-class performance on six tasks: image super-resolution (classical, lightweight, and real-world), image denoising (grayscale and colour picture denoising), and JPEG compression artefact elimination. In this part, we’ll look at how effective SwinIR is and compare it to prior SOTA approaches like ESRGAN and BSRGAN.
- Let’s clone all the repositories and set up the environment.
# Clonning real-ESRGAN, BSRGAN, SwinIR !git clone https://github.com/xinntao/Real-ESRGAN.git %cd Real-ESRGAN !git clone https://github.com/cszn/BSRGAN.git !rm -r SwinIR !git clone https://github.com/JingyunLiang/SwinIR.git !pip install timm # install the dependencies !pip install basicsr !pip install facexlib !pip install gfpgan !pip install -r requirements.txt !python setup.py develop # Get the pre-trained models !wget https://github.com/cszn/KAIR/releases/download/v1.0/BSRGAN.pth -P BSRGAN/model_zoo !wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth -P experiments/pretrained_models !wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth -P experiments/pretrained_models !wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth -P experiments/pretrained_models import os import glob from google.colab import files import shutil
- Now let’s upload the image which will be processed by all three architectures.
# test SwinIR by partitioning the image into patches
test_patch_wise = False
# to be compatible with BSRGAN
!rm -r BSRGAN/testsets/RealSRSet
upload_folder = 'BSRGAN/testsets/RealSRSet'
result_folder = 'results'
if os.path.isdir(upload_folder):
shutil.rmtree(upload_folder)
if os.path.isdir(result_folder):
shutil.rmtree(result_folder)
os.mkdir(upload_folder)
os.mkdir(result_folder)
# upload images
uploaded = files.upload()
for filename in uploaded.keys():
dst_path = os.path.join(upload_folder, filename)
print(f'move {filename} to {dst_path}')
shutil.move(filename, dst_path)
- Here is our uploaded image which is quite suitable for restoration.

- Now let’s process this image for all models
# BSRGAN
!rm -r results
#test_patch_wise = True
if not test_patch_wise:
%cd BSRGAN
!python main_test_bsrgan.py
%cd ..
shutil.move('BSRGAN/testsets/RealSRSet_results_x4', 'results/BSRGAN')
# realESRGAN
if test_patch_wise:
!python inference_realesrgan.py --model_path experiments/pretrained_models/RealESRGAN_x4plus.pth --input BSRGAN/testsets/RealSRSet --netscale 4 --output results/realESRGAN --tile 800
else:
!python inference_realesrgan.py --model_path experiments/pretrained_models/RealESRGAN_x4plus.pth --input BSRGAN/testsets/RealSRSet --netscale 4 --output results/realESRGAN
# SwinIR
if test_patch_wise:
!python SwinIR/main_test_swinir.py --task real_sr --model_path experiments/pretrained_models/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth --folder_lq BSRGAN/testsets/RealSRSet --scale 4 --tile 800
else:
!python SwinIR/main_test_swinir.py --task real_sr --model_path experiments/pretrained_models/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth --folder_lq BSRGAN/testsets/RealSRSet --scale 4
shutil.move('results/swinir_real_sr_x4', 'results/SwinIR')
# SwinIR-Large
if test_patch_wise:
!python SwinIR/main_test_swinir.py --task real_sr --model_path experiments/pretrained_models/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq BSRGAN/testsets/RealSRSet --scale 4 --large_model --tile 640
else:
!python SwinIR/main_test_swinir.py --task real_sr --model_path experiments/pretrained_models/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq BSRGAN/testsets/RealSRSet --scale 4 --large_model
shutil.move('results/swinir_real_sr_x4_large', 'results/SwinIR_large')
for path in sorted(glob.glob(os.path.join('results/SwinIR_large', '*.png'))):
os.rename(path, path.replace('SwinIR.png', 'SwinIR_large.png'))
Now let’s see how real-ESRGAN, BSRGAN, and SwinIR performed. The code snippets to visualize the result is available here.
Output of real-ESRGAN

Output of BSRGAN

Output of SwinIR

Final Words
Through this post, we have seen an overview of the Image reconstruction technique. Specifically, we have discussed what is image restoration, how it is evolved and addressed by various techniques such as CNN, Transformer, etc. In contrast to the transformer, we have seen a Working of SwinIR theoretically and practically it has shown how it outperforms real-ESRGAN. Results of SwinIR and BSRGAN are relatively close to each other.