Before diving into the definition of natural language processing it is extremely important to explore why it came into existence. Our personal computers communicate in a language known as machine language. Unlike human natural language, a machine language uses a series of zeroes and ones often called bits to communicate to the outer world and is vaguely puzzling for humans. To bridge this gap it was necessary for machines to act and talk like humans and hence NLP was invented to proffer intelligent human to machine interaction.
What is Natural Language Processing (NLP)?
Natural language processing is a subset of Artificial Intelligence, Computer science and Human linguistic processing providing the ability for computers/ machines to understand, process and acquire significant insights from human natural languages.
In this era, NLP is scaling exponentially in vast areas such as defence, finance, entertainment, healthcare, automation, etc.
Significance
Regularly humongous amounts of data are generated in our system in real-time using transactions, sensors, devices, dialects, etc. The generated data is highly unstructured data. NLP allows us to make this data manageable, less ambiguous and analyse the data at a much faster rate as compared to humans.
NLP proffers an advancement in interpreting, reading and hearing the human-oriented data, to extract sentiments and outcomes from it.
Applications of Natural Language Processing
The significance of NLP is better understood by exploring its real-life applications.
- Social media analysis measures and classifies sentiments over online data so that we can target toxic comments or cyberbullying, forecast and analyse major influences driving the social media communities. Companies also use sentiments to track their product or service behaviour in the market.
- Text analytics are employed in organizations to identify customer dissatisfaction and classify the customers so that the company can implement improvements and serve their consumers even better.
- Fraud analytics is used in document search and banking systems to restrict and detect fraudulent behaviour. Multinational companies use NLP to detect and classify unusual activities, for example how our mailing systems such as Gmail and Rediffmail categorize spam emails in your inbox.
- Speech interfacing to understand and act on speech prompts given by humans. Virtual agents like Microsoft’s Cortana and Amazon’s Alexa use their speech recognition and NLU techniques to create your shopping list, give you weather updates, etc.
- Machine Translation using NLP is used to auto-translate source language to another desired language such as google translate.
- Digital marketing/ campaigning exploits data-driven NLP methods to automate and dig into customer/ target audience portfolios, social media market research to build their content strategies. for example chatbot assistance as a recommender.
NLP Libraries and Techniques
- Libraries: NLP is effectively implemented using programming languages such as Python and R. Let’s look at some common, ready to use packages/libraries used for NLP in R and Python.
- R libraries:
- TM is a text mining library which is used extensively to perform data preprocessing and mapping techniques. tm houses various functions for text and metadata analysis.
- languageR contains functions to perform statistical analysis on the textual data. It provides built-in functions to implement correlation, regression techniques.
- Dplyr is a data manipulation library that offers functions to filter, arrange and sample the dataset so it smooths out data manipulation and processing.
- Lsa library is used to perform latent semantic analysis in R. Decomposing a document feature matrix is an exceptional feature of lsa which clearly represents semantic behaviour of the data.
- Python Libraries
- NLTK natural language toolkit as the name suggests is an essential toolkit for numerous NLP tasks ranging from parsing, stemming up to classification and clustering.
- CoreNLP library is one of the fastest libraries for NLP written in java. It performs major tasks such as POS tagging, dependency parsing and supports several other languages besides English
- Spacy library supports built-in ready to use statistical models and NLP pipeline which automates preprocessing activities such as tagging, tokenizing, NER, etc.
- TextBlob is a beginner level library that can be used to implement basic analysis tasks in R.
Now, let’s learn and implement some NLP techniques provided by such libraries.
NLP Techniques
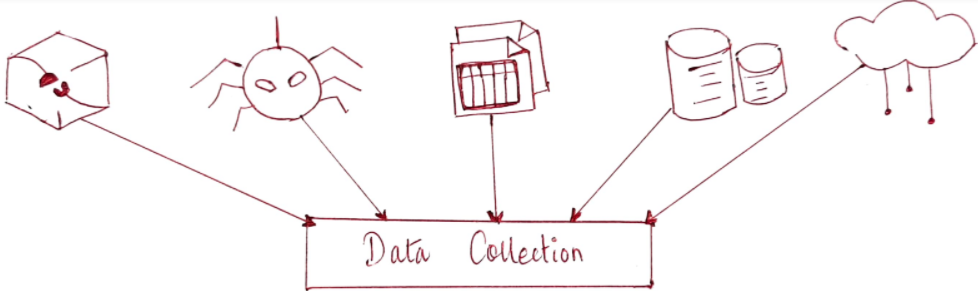
1. Data Collection
To perform linguistic processing over any problem statement first you should acquire the data set relevant to the problem. Data collection involves activities to retrieve specific information from the big data. NLP uses common methods such as APIs, web scrapers, plugins and existing datasets/databases to gather data for processing.
2. Data Segmentation
NLP is a collection of preprocessing and analysis. In order to attain near accurate results, it is essential to preprocess the data for anomalies and refine it. Segmentation is a technique to fragment the dataset using separators so to get a clear picture. Default separators are commas or full stops.
3. Tokenization
It is a process of further segmenting the data by converting sentences into a sequence of separate words referred to as tokens and getting rid of punctuation characters.
from nltk import word_tokenize, sent_tokenize
data = “It is an amazing story about the journey to ones destiny. It inspires you to achieve your dreams, work hard for it and see how the entire universe conspires to make it happen”
print(“word tokenization”)
print(word_tokenize(data))
print(“segmentation”)
print(sent_tokenize(data))


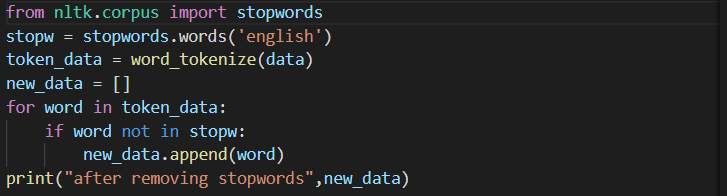
4. Stop Words Removal
Generally the raw data set contains some dialects or words which provide meaning while conversing but depict little or no meaning when it comes to processing, in such situations NLP uses technique called stop words removal to remove non important grammar words example or, and, the, are ,etc. This technique performs data sanitization over the data set to keep it concise and accurate.

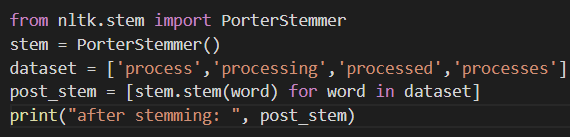
5. Stemming
Stemming is another technique of preprocessing which is used to reduce a word to its stem word by removing affixes added. Stemming is an important practice since affixes can increase the dimensionality of the data which is undesirable.

6. Lemmatization
It is a NLP technique to reduce any word to its root word. Lemmatization maps different dictionary words to its cognitive set as ‘was’,’are’,’is’ is reduced to ‘be’.


7. Dependency Detection
This method is implemented after preprocessing, a method used to establish and identify possible relationships between words in a data set.
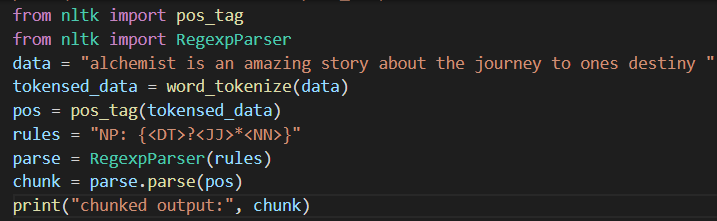
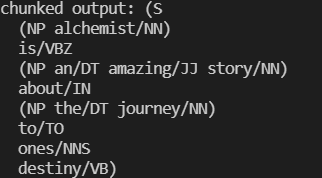
8. Chunking
Chunking is a method in NLP which takes words in unstructured data as an input and groups them into a chunk or a cluster of parts of speech.It is used to retrieve phrases from a description. In a scenario for a sentence “We had chicken and curry for dinner” if you want to chunk nouns it will output a set of “chicken curry dinner”.
Conclusion
In this article, we grasped the basics of Natural Language processing, its importance in computational linguistics and its usage in handling voluminous unstructured textual data.
NLP has gained a lot of credibility in the area of data science and analysis due to its immense development and hence it is essential to master the NLP technology.